
Vector search innovates information retrieval by prioritizing semantic meaning over keywords, converting diverse data (text, images, audio, video) and user queries into mathematical vectors, or embeddings, whose proximity, measured by similarity metrics via nearest neighbor (NN) algorithms (often Approximate NN or ANN for speed with large datasets), enables context-aware, semantic retrieval. This process hinges on the foundational role of embeddings—numerical translations capturing semantic relationships—and utilizes vector indexes for efficient searching.
Key concepts include the vector itself (a high-dimensional data point), the embedding process, NN search, similarity metrics (like cosine similarity, Euclidean distance, and dot product), and the connection to semantic search which understands user intent. Unlike traditional keyword search's literal matching, vector search offers deeper contextual understanding, making a significant impact in text/document analysis, image/multimedia retrieval, recommendation engines, and generative AI/LLMs (e.g., through Retrieval Augmented Generation - RAG), with emerging applications in anomaly detection and scientific research. The future outlook for vector search includes multimodal capabilities, becoming a standard developer tool, integration into edge computing, and the development of AI agents capable of complex problem-solving.
How does vector search work?
To get how vector search operates, picture a multi-step journey. It takes raw data and what you type into the search box, then converts both into a special format where their similarity in meaning can be accurately measured. This conversion is what lets systems figure out and fetch information based on what it means, not just the exact words used.
What is the role of chunking in vector search?
Before data can be embedded, it must be prepared. Large documents cannot simply be converted into a single vector without losing nuance. This is where chunking comes in. The text is broken down into smaller, manageable pieces—sentences, paragraphs, or fixed-token windows. Each chunk is then individually converted into a vector. This granular approach ensures that when a user asks a specific question, the system retrieves the precise segment of information containing the answer, rather than returning a vague 50-page document.
Deep Dive: What is the HNSW Algorithm?
While there are several algorithms for Approximate Nearest Neighbor search (like IVF or Annoy), Hierarchical Navigable Small Worlds (HNSW) is currently the industry standard for speed and accuracy.
To understand HNSW, imagine a multi-layer map of a city:
- The Top Layer (Highways): Contains very few data points with long connections. This allows the search algorithm to jump across vast distances of the dataset quickly.
- The Middle Layers (Arterial Roads): As the algorithm gets closer to the target, it drops down to lower layers where data points are denser.
- The Bottom Layer (Local Streets): This layer contains every single data point. By the time the search reaches this level, it is already in the correct "neighborhood," allowing for a precise final search.
What is the foundational role of embeddings in vector search?
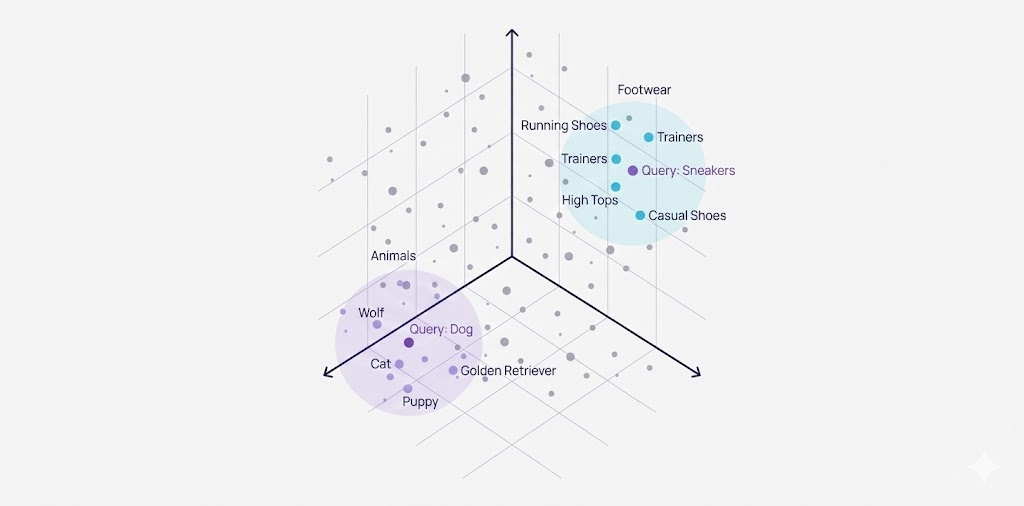
Embeddings are the real engine driving vector search. Think of them as numerical translations: things like words, sentences, whole documents, pictures, or even user profiles get turned into these vector forms by smart machine learning models. What's particularly important about these embeddings is how they manage to bottle up the semantic connections between different bits of data. If two items mean something similar, their embeddings will naturally sit closer together in this extensive, multi-dimensional vector space.
How is a user query converted to a vector?
When you type in a search, your query goes through the exact same transformation. The very same embedding model that processed all the database content gets to work, turning your search terms into a vector too. This step is important because it makes sure both the stored data and your query are on the same page—in the same dimensional space, using the same vector 'language'—so they can be directly compared. This foundational process is what powers effective natural language search.
How is proximity measured between vectors?
With your query now a vector, the main job for vector search is to find the database vectors that are 'closest' to it. This matching game is usually handled by nearest neighbor (NN) algorithms. These algorithms use mathematical formulas, called similarity metrics, to measure just how 'close' or similar two vectors are. We'll discuss these metrics in more detail later when we cover key terms.
How does this process enable semantic retrieval?
Because the system focuses on how close vectors are (as measured by those similarity metrics), it pulls up items that are semantically similar to what you searched for. In plain English, the results match the meaning or context of your query, not just the exact keywords which is a key aspect of achieving strong search relevance. For example, if you search for "ways to stay fit without a gym," you might get articles about home workouts, jogging, or bodyweight exercises, even if none of them use that exact phrase.

What are the key terms and concepts in vector search?
To really get a handle on vector search, it helps to know some of the lingo. These key terms explain the core pieces and how they work together to make this technology so effective.
What is a vector in the context of search?
When we talk about vector search, a vector is basically a list of numbers that plots an item (like a word, document, or picture) as a point in a high-dimensional space. Each number in that list, or each dimension, stands for a particular characteristic of the item. These vectors, often just called embeddings, have both direction and length, and it's this combination that represents an item's semantic characteristics and its relationships to others.
What does embedding mean in vector search?
Embedding is a term that wears two hats in vector search: it's both the act of turning data into vectors and the vector you end up with. Usually, machine learning models like neural networks do this translation work, having learned from massive datasets how to create representations that make sense. How well this embedding step is done is make-or-break for vector search, because it dictates how accurately the meaning and connections between data are caught.
What is the nearest neighbor (NN) search?
Nearest neighbor (NN) search is the algorithm's job of sifting through a dataset to find the data points (vectors) that are the closest match to your query vector, based on a specific similarity measure. At its core, vector search is a type of nearest neighbor search. You can do it precisely, which guarantees you find the very closest matches, or you can do it approximately, which speeds things up considerably for large datasets, even if it's not 100% perfect.
How do similarity metrics quantify relationships?
Similarity metrics are the math formulas that crunch the numbers to figure out just how close or alike two vectors are. We touched on some common ones earlier, like:
- cosine similarity: this looks at the angle between two vectors. A score of 1 means they point in the exact same direction, 0 means they're unrelated (at a right angle), and -1 means they point in opposite directions,
- Euclidean distance: this is your everyday straight-line distance between two points in that vector space. The shorter the distance, the more similar they are,
- Dot product: This calculates the sum of the products of corresponding entries in two sequences of numbers. It favors vectors with larger magnitudes (length). It is computationally faster and highly effective for recommendation engines where the magnitude (e.g., popularity or rating intensity) is as important as the direction.
Which metric you pick often comes down to what kind of data you're working with and the specific embedding model that created the vectors.
What is semantic search and its connection to vectors?
Semantic search is all about understanding what a user means by their query—the intent and context—instead of just hunting for exact keyword matches. Vector search is one of the main technologies that makes semantic search possible. By turning both data and queries into vectors that represent their semantic content, vector search lets systems fetch results that are related by concept, even if the wording is completely different.
Why use approximate nearest neighbor (ANN) search?
When you're dealing with extensive datasets and vectors with tons of dimensions, finding the absolute exact nearest neighbor can be a real drag on computer resources and take forever. That's where Approximate Nearest Neighbor (ANN) search algorithms come in handy. They offer a clever workaround by finding vectors that are probably among the closest, giving up a tiny bit of pinpoint accuracy in exchange for much, much faster searches. For most real-world uses where speed matters, this trade-off is usually a good deal and often necessary.
What is the function of a vector index?
Think of a vector index as a smart filing system specifically built to store and arrange vectors so that finding the nearest neighbors is super fast. It's a lot like how regular databases use indexes to make looking up data quicker. Vector indexes let systems efficiently comb through millions, or even billions, of vectors without the slog of comparing your query vector to every single one in the database. There are different ways to build these indexes, and each method has its own pros and cons when it comes to speed and performance.

How does vector search compare to traditional keyword search?
Understanding how vector search differs from old-school keyword search is key to seeing why it's such a big deal.
1. Matching Method:
- Traditional Keyword Search: Uses literal term or substring matching.
- Vector Search: Uses semantic similarity using vector proximity.
2. Query Understanding:
- Traditional Keyword Search: Is surface-level, meaning words must appear as typed.
- Vector Search: Is contextual, understanding intent and related meaning.
3. Use Case Example:
- Traditional Keyword Search: Searching for "best pizza restaurant" returns results containing those exact words.
- Vector Search: Searching for "best pizza restaurant" returns highly-rated pizza places even if different wording is used (e.g., "top-rated pizzeria," "great local pizza spots").
4. Underlying Data Model:
- Traditional Keyword Search: Uses text indexes (e.g., inverted index).
- Vector Search: Uses vector/embedding indexes.
As you can see, vector search isn't just about matching words; it's a leap towards a much smarter, meaning-based way of finding information.
This capability to understand intent is a hallmark of advanced search systems, such as modern AI-powered site search.
Why is Hybrid Search the new standard?
While vector search is powerful, it isn't perfect. It can sometimes struggle with exact matches, such as specific product model numbers (e.g., "Sony WH-1000XM5") or jargon that hasn't been learned by the embedding model. This is where Hybrid Search comes in.
Hybrid search combines the best of both worlds:
- Keyword Search (Lexical): Ensures precision for exact terms, filters, and hard constraints.
- Vector Search (Semantic): Ensures recall by capturing intent, context, and synonyms.
By running both searches simultaneously and merging the results using a ranking algorithm like Reciprocal Rank Fusion (RRF), systems can deliver results that are both contextually aware and precise. For example, in e-commerce, a user searching for a "cheap red dress" needs the semantic understanding of "dress" (vector) but the strict filtering of "cheap" and "red" (keyword/metadata).
Where is vector search making an impact: real-world examples
Vector search isn't just some abstract idea—it's already out in the wild, integral to many applications and showing just how useful and transformative it can be.
How is vector search applied in text search and document analysis?
When it comes to sifting through text, vector search lets you find articles, documents, or even specific paragraphs based on what your query means, not just because they share the same keywords. Imagine searching for "philosophical novels about artificial consciousness." Vector search could point you to books on AI ethics and machine sentience, even if those exact words aren't in the book summaries. This kind of understanding is a huge help for researchers, anyone trying to discover new information, and for building smart Q&A systems.
How is vector search used for image and multimedia retrieval?
In the world of images, vector search lets you find pictures that look alike. You can upload an image, it gets turned into a vector, and then the system hunts down other images with similar vector fingerprints. This is the magic behind "search by image" features and content-based image retrieval (CBIR) systems. And it doesn't stop at pictures; the same idea applies to finding similar audio and video clips based on their meaning.
How does vector search enhance recommendation engines?
Recommendation engines—the ones suggesting what to buy, watch, or read on e-commerce sites, streaming services, and content platforms—get a big boost from vector search. Both your preferences and the details of items (like products, movies, or articles) are turned into vectors. By matching your 'interest' vector against the vectors of various items, the system can recommend things you're probably going to like, even if you've never looked for something with those exact keywords before.
What is the role of vector search in generative AI and large language models (LLMs)?
Vector search plays a key part in many generative AI tools, like sophisticated chatbots and virtual assistants. When Large Language Models (LLMs) need to pull specific facts from a big, private collection of information to answer your questions or write something, vector search quickly finds the most relevant snippets or documents. This technique, known as Retrieval Augmented Generation (RAG), helps make LLM answers more accurate, current, and based on real data.
What are other emerging applications of vector search?
It's not just in these well-known fields; vector search is also showing its worth in some pretty specialized areas. For instance, anomaly detection systems use it to spot unusual activity by finding data points that stick out from the crowd in vector space. And in scientific fields like drug discovery and genomics, things like molecular structures or DNA sequences can be turned into vectors. This helps scientists find similarities and predict how they might interact, speeding up the whole research and development process.
What is the future outlook for vector search?
Vector search is heading toward some pretty exciting territory. The biggest shift we're likely to see is multimodal capabilities—where you could ask something like "find product demos where customers look genuinely excited" and actually get results that analyze facial expressions, tone of voice, and visual cues all at once. It's wild when you think about it.
By 2027 or 2028, vector databases will probably be just another tool in the developer toolkit, right alongside PostgreSQL and MongoDB. Amazon, Google, and Microsoft are already racing to make this happen. But here's what's fascinating: edge computing is bringing this tech directly to your phone and smart devices. No internet? No problem—your device will handle semantic search locally.
The real game-changer, though, might be AI agents that can actually understand what you're trying to accomplish across multiple steps. Instead of just finding documents, they'll navigate through entire knowledge systems to solve complex problems. That's going to change how we work with information completely—both at the office and at home.
Frequently Asked Questions (FAQ)
When should you use vector search?
You should use vector search when your application requires understanding user intent rather than just matching exact words. It is ideal for large datasets involving unstructured data (images, long text, audio), building recommendation engines, or implementing Retrieval Augmented Generation (RAG) for AI chatbots where context is critical.
What is the difference between semantic search vs. vector search?
Semantic search is the goal, while vector search is the method. Semantic search refers to the capability of a system to understand meaning and context. Vector search is the specific technology (using mathematical embeddings and distance metrics) used to achieve that semantic understanding.
How do you implement vector search?
Implementing vector search involves four key steps:
- Chunking: Break your data into manageable segments.
- Embedding: Use an embedding model (like OpenAI’s text-embedding-3 or Hugging Face models) to convert data into vectors.
- Indexing: Store these vectors in a Vector Database.
- Querying: Convert user queries into vectors and use Approximate Nearest Neighbor (ANN) algorithms to retrieve the closest matches.




